
Domain driven design and microservices belong together and they go hand in hand, so as part of an overall architecture strategy, it’s important to consider how you are structuring your components, or in the case of a monolith or existing solution, how you decompose that into a set of useable Microservices. This document will serve as a starting point and introduction to core Microservices topics which will be linked to in future articles where I dive deeper into patterns and practices.
A microservice is a “small” service that can be independently developed, deployed, and tested. They are very suitable for and often deployed as part of automated CI/CD DevOps pipelines. Your overall Microservice or API strategy will consist of multiple Microservices as part of an overall API architecture, but where do you start when building it out?
You will need to understand the goal and why you are thinking about building a microservice architecture in the first place. Some considerations to think about are outlined in my article from 2018 titled Considerations for Moving to Microservices where things like organizational maturity, team capabilities, and risks are indicated.
Although there are some standard and usual patterns when building microservices patterns and the core idea of what constitutes a microservice is well known and documented, as the architect, your technical direction and leadership sets the tone and the standard for your client or organization. Documenting and presenting content to get team, client, and organizational buy-in is important and will get everyone on the same page, and chances are it will be a relatively easy sell to the development and testing teams, and it will have the added benefit of getting people less familiar with the Microservices concept up to speed with it.
A fundamental concept regarding microservices is the identification of what exactly constitutes a microservice, and this is where domain driven design concepts like bounded contexts and aggregates come in. Consider a bounded context as representative of related functions or business activities within an organization that is mapped to a component or service. A bounded context may have one or more aggregates in which aggregates are related pieces of business or functionality that could be logically grouped within a boundary. A good example of this is Order and Order Items; both of these are aggregates and could belong within a single “Orders” bounded context, however, it is not necessarily so, and microservices can be more or less finely grained than that depending in the goals and constraints of the architecture.
There is no right or wrong answer as to how broadly or narrowly scoped your bounded contexts are, but there are established norms when building microservices that they need to be reasonably sized and reasonably scoped. Let’s consider use cases for a regional passenger train operator and how we can start to architect microservices and identify their bounded contexts.
The first use cases and data entities revolve around payments. Someone buys a train ticket and then needs to pay for it. They make a payment and ultimately that information gets funnelled into some back end systems.
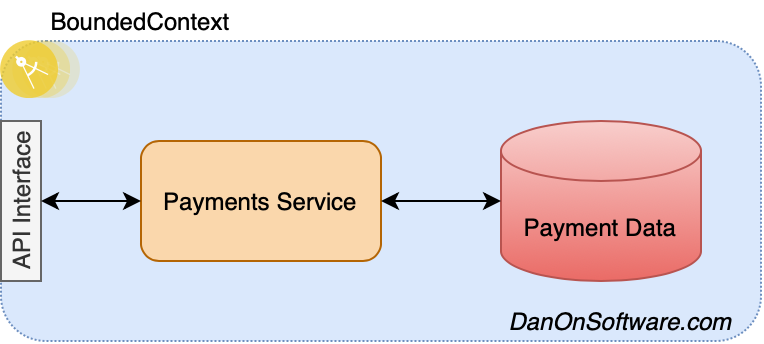
As you build out the architecture, everything else needs to start to come into place, so you start thinking about additional aggregates that may need to be included as part of payments. You start to look at reservations. Should reservations be a part of payments? Is it really an aggregate of payments? That’s for you to decide, but I would say it is not although since there is no hard and fast rule for how large your bounded context should be, you could add reservations as part of the same microservice and keep functionality related to both payments and reservations inside that microservice. Let’s take a look.
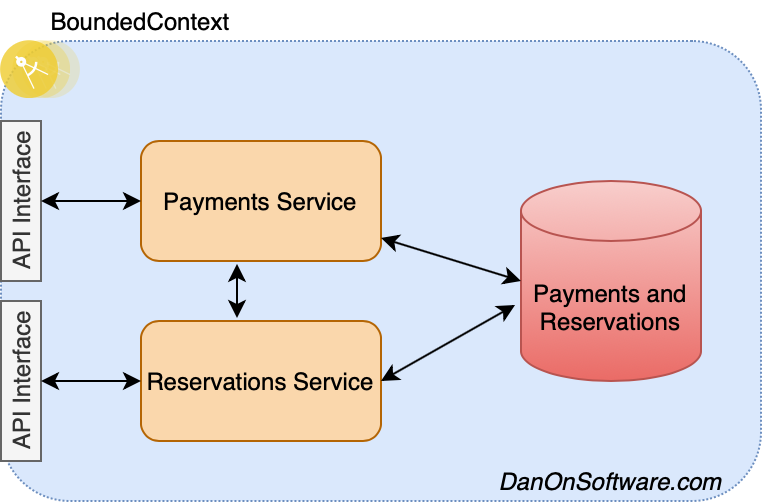
It’s getting kind of bulky, and the validity of this as a proper microservice would be disputed, but this may be acceptable and is completely dependant on your needs. However, we soon realize that Reservations are also dependant on a Schedule. You can’t reserve a seat on a train unless that train has been scheduled. So, we continue down the road and add a schedule component within this bounded context.
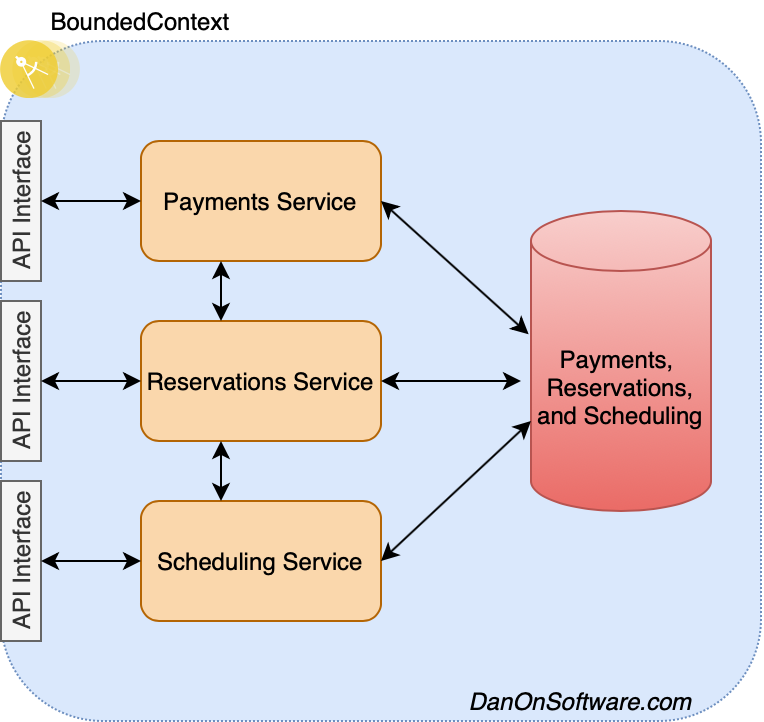
Now, our microservice architecture is really starting to bulk out and we are definitely heading into anti-pattern territory here if we let this thing get too big. However, there is an important distinction to be made here and that is that even though we seem to have bungled more than we probably should into a single microservice, the microservice itself is inherently less complex from a development and usage standpoint than it would otherwise be, and that’s because there is more leeway in the service itself for cross communication and bungling data together without having to implement more complex patterns with more moving parts. This comes with other costs, however.
This example above isn’t necessarily wrong and there may be a good case for why this could be considered as part of a microservice architecture, but the reasoning here really needs to be considered and well thought out. The whole point of microservices is to create reasonable bounded contexts for your services to live in while understanding and identifying additional patterns needed.
As per the above, there is also nothing wrong with this being part of an evolutionary pattern to a full microservice architecture, and you could loosely consider the above as a microservice with a large bounded context, or consider it as a way to modularize your business domains while keeping them in a single service only to be decomposed later into their own microservices as your solution and organization evolves.
As you continue on in the evolution of your microservice architecture, you may be defining interim and future target states which take on some of the life forms discussed in this article or new life forms all together. In the train ticketing example, as we move along in our evolution, we will identify and design the target state architecture which conform to new sets of API and microservices standards.
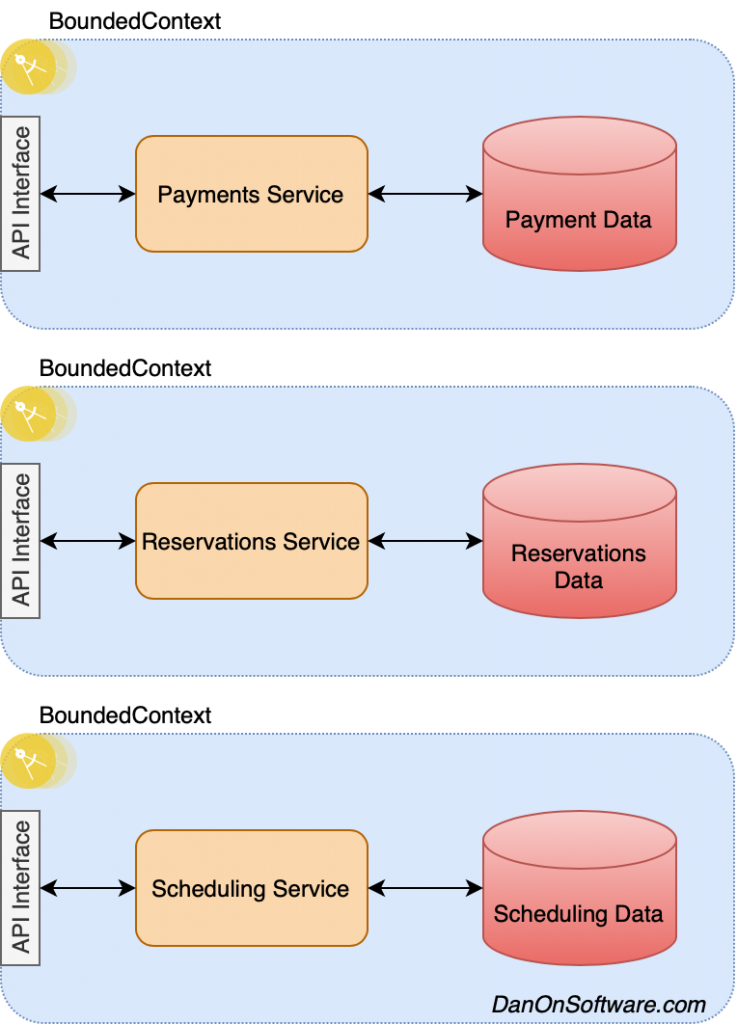
There are additional patterns that need to be taken into consideration here as well because the more we decompose the solution into sets of microservices, the more complexity there is when considering reporting, performance, workflows, cross domain data, and distributed transactions.
These concepts are very important to understand and need to be considered along with the entire microservice architecture roadmap. Teams need to be clear on the patterns to approach these problems, and understand the complexity that is added the more finely grained your services become. Eventual consistency data models need to be considered and additional patterns may be required, include, CQRS, SAGA, and others. (These will all be eventually written about here on this blog, and I will update this article with links when available).